
Founder: Brendan Eich
Currently Used Compiler in Web Browsers are JIT (Just-In-Compiler).
Chakra, SpiderMonkey, V8 are some the javascript engine used by Microsoft Edge,Firefox and Chrome respectively

Compiler Vs Interpreter

Compiler generates machine code by compiling the program without running it. It compiles whole program to run.
Interpreter Generates bytecode that can be read by Javascript Engine to perform task. Also it runs on the fly. It interpret line by line and if any error occurs it throws it back at that line.
Inside Chrome V8 Engine

Write always optimzed code from you developer side so that it get easy to compile in compiler.
Use Inline Caching and Hidden Classes
//Hidden Classes
function Name(first,last){
this.first=first;
this.last=last;
}
const name1 = new Name("Suripie","Coder");
const name2 = new Name("Dave","Buster");
//Untill now there is shared hidden class is present
name1.salutation = "Mr";
//Now it does not have it. But if i declare same for name2 then it will //have shared hidden class
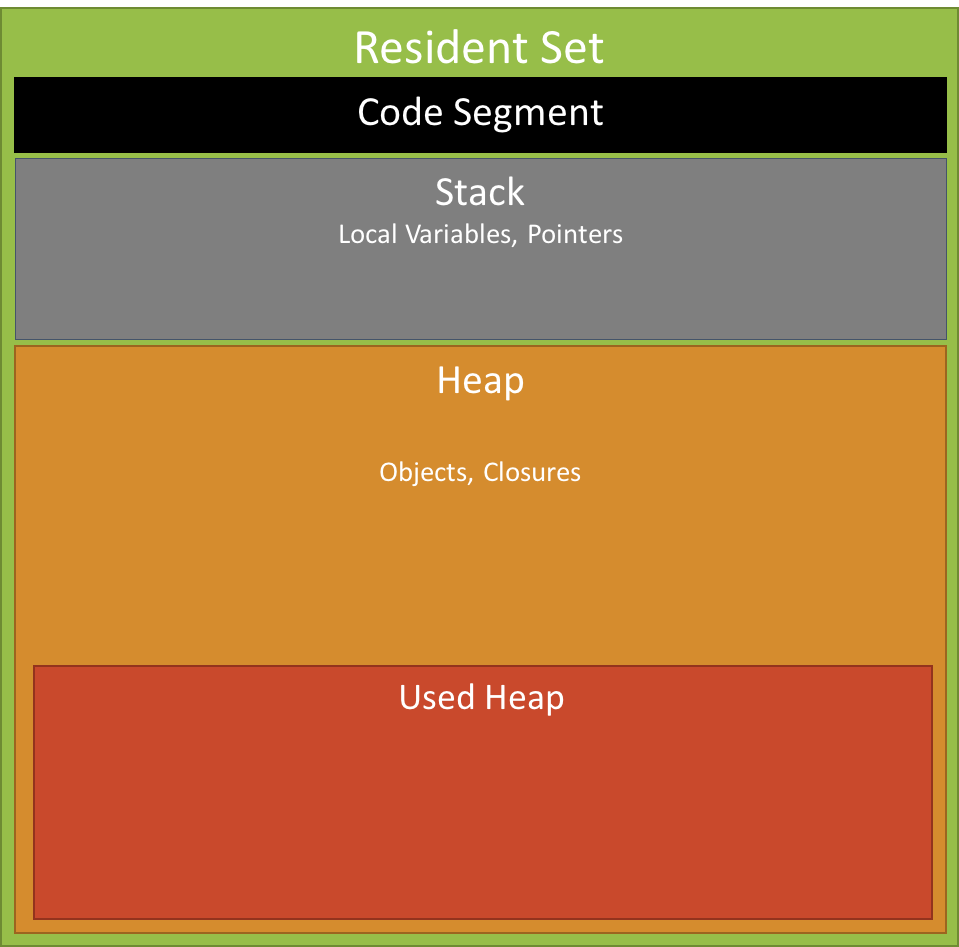
Call Stack and Memory Heap

Memory Heap
Stack Overflow
Recursion can be used to make Stack Overflow. When memory of stack gets full. It happens because functions are not exiting and keep piling up.
//Cause Stack Overflow Error
function Recursion(){
Recursion()
}
Recursion()Garbage Collection

Garbage Collector automatically sweeps the unlinked variables and makes heap memory free.
Memory Leaks
Three main reasons of memory leaks.
- Global variables
- Event Listeners
- setInterval
- Global Variables
Global variables and function names are an incredibly bad idea. The reason is that every JavaScript file included in the page runs in the same scope. If you have global variables or functions in your code, scripts included after yours that contain the same variable and function names will overwrite your variables/functions.
There are several workarounds to avoid using globals — we’ll go through them one by one now. Say you have three functions and a variable like this:
var current = null;
function init(){...}
function change(){...}
function verify(){...}
You can protect those from being overwritten by using an object literal:
var myNameSpace = {
current:null,
init:function(){...},
change:function(){...},
verify:function(){...}
}
This does the job, but there is a drawback — to call the functions or change the variable value you’ll always need to go via the name of the main object: init() is myNameSpace.init(), current is myNameSpace.current and so on. This can get annoying and repetitive.
It is easier to wrap the whole thing in an anonymous function and protect the scope that way. That also means you don’t have to switch syntax from function name() to name:function(). This trick is called the Module Pattern:
myNameSpace = function(){
var current = null;
function init(){...}
function change(){...}
function verify(){...}
}();
Again, this approach is not without issues. None of these are available from the outside at all any more. If you want to make them available you need to wrap the things you want to make public in a return statement:
myNameSpace = function(){
var current = null;
function verify(){...}
return{
init:function(){...}
change:function(){...}
}
}();
That pretty much brings us back to square one in terms of linking from one to the other and changing syntax. I therefore prefer to do something like the following (which I dubbed the “revealing module pattern”):
myNameSpace = function(){
var current = null;
function init(){...}
function change(){...}
function verify(){...}
return{
init:init,
change:change
}
}();
Instead of returning the properties and methods I just return pointers to them. This makes it easy to call functions and access variables from other places without having to go through the myNameSpace name.
It also means that you can have a public alias for a function in case you want to give it a longer, descriptive name for internal linking but a shorter one for the outside:
myNameSpace = function(){
var current = null;
function init(){...}
function change(){...}
function verify(){...}
return{
init:init,
set:change
}
}();
Calling myNameSpace.set() will now invoke the change() method.
If you don’t need any of your variables or functions to be available to the outside, simply wrap the whole construct in another set of parentheses to execute it without assigning any name to it:
(function(){
var current = null;
function init(){...}
function change(){...}
function verify(){...}
})();
This keeps everything in a tidy little package that is inaccessible to the outside world, but very easy to share variables and functions inside of.
2. Event Listeners
Event listeners added to element in any Single Page Application and if not removed can cause memory leaks. Its because event listeners gets added when user navigate site back and forth.
3. Something Like setInterval
Something like setInterval function keeps calling itself after a interval and finally causing a stack overflow.
Javascript Runtime Environment

AJAX, the DOM tree, and other API’s, are not part of Javascript, they are just objects with properties and methods, provided by the browser and made available in the browser’s JS Runtime Environment.
The Javascript Runtime Environment
Think of the JS runtime environment as a big container. Within the big container are other smaller containers. As the JS engine parses the code it starts putting pieces of it into different containers.

The Heap
The first container in the environment, which is also part of the V8 JS Engine, is called the ‘memory heap.’ As the V8 JS Engine comes across variables and function declarations in the code it stores them in the Heap.
The Stack
The second container in the environment is called the ‘call stack.’ It is also part of the V8 JS Engine. As the JS Engine comes across an actionable item, like a function call, it adds it to the Stack.
Once a function is added to the Stack the JS engine jumps right in and starts parsing its code, adding variables to the Heap, adding new function calls to the top of the stack, or sending itself to the third container where Web API calls go.
When a function returns a value, or is sent to the Web API container, it is popped off the stack and moves to the next function in the stack. If the JS Engine gets to the end of the function and no return value is explicitly written, the JS Engine returns undefined and pops off the function from the stack. This process of parsing a function and popping it off the stack is what they mean when they say Javascript runs synchronously. It does one thing at a time on a single thread.
Note – the Stack is a data structure that runs LIFO — last in first out. No function other than the one at the top of the stack will ever be in focus, and the engine will not move to the next function unless the one above it is popped off.
The Web API Container
The Web API calls that were sent to the Web API container from the Stack, like event listeners, HTTP/AJAX requests, or timing functions, sit there until an action is triggered. Either a ‘click’ happens, or the HTTP request finishes getting its data from its source, or a timer reaches its set time. In each instance, once an action is triggered, a ‘callback function’ is sent to the fourth and final container, the ‘callback queue.’
The Callback Queue
The Callback Queue will store all the callback functions in the order in which they were added. It will ‘wait’ until the Stack is completely empty. When the Stack is empty it will send the callback function at the beginning of the queue to the Stack. When the Stack is clear again, it will send over its next callback function.
Note – the Queue is a data structure that runs FIFO — first in first out. Whereas the Stack uses a push and pop (add to end take from end), the Queue uses push and shift (add to end take from beginning).
The Event Loop
The Event Loop can be thought of as a ‘thing’ inside the javascript runtime environment. Its job is to constantly look at the Stack and the Queue. If it sees the Stack is empty, it will notify the Queue to send over its next callback function. The Queue and the Stack might be empty for a period of time, but the event loop never stops checking both. At any time a callback function can be added to the Queue after an action is triggered from the Web API container.
This is what they mean when they say Javascript can run asynchronously. It isn’t actually true, it just seems true. Javascript can only ever execute one function at a time, whatever is at top of the stack, it is a synchronous language. But because the Web API container can forever add callbacks to the queue, and the queue can forever add those callbacks to the stack, we think of javascript as being asynchronous. This is really the great power of the language. Its ability to be synchronous, yet run in an asynchronous manner, like magic!
Blocking vs Non-Blocking I/O
When we talk about blocking I/O, think of an infinite loop, where a function just keeps running. If the function never stops running then it will never get popped off the stack, thus ‘blocking’ the next function in the stack from ever running. Another possibility is running a function that has so much complex logic and calculations, it thus takes so much time to run that it ‘blocks’ the next function from running. These are things to be aware of when creating code, but these are more programming errors and poorly written code that block i/o, rather than it being the fault of the language.
One thing that can be a ‘blocking i/o’ is an HTTP request. Say you make a request to some external site data and you have to wait for that site’s network. The network may never respond and your code will ultimately be stuck. But Javascript handles this in the runtime environment. It sends the HTTP request to the Web API and pops it off the stack so that the next function can run while the Web API waits for its data to return. If the HTTP request never gets its data back the rest of the program will continue running. This is what we mean when we say JS is a Non-Blocking language.
